-
AggregateDatabase/MongoDB 2023. 2. 1. 20:39
Aggregate 란?
aggregate는 Pipeline 개념을 모델로 하며 Collection 이나 Database 의 데이터를 가공하는 기능입니다.
각 단계별로 진행을 마친 후 결과를 반환하며, 각 단계는 Stage 라고 명명합니다.
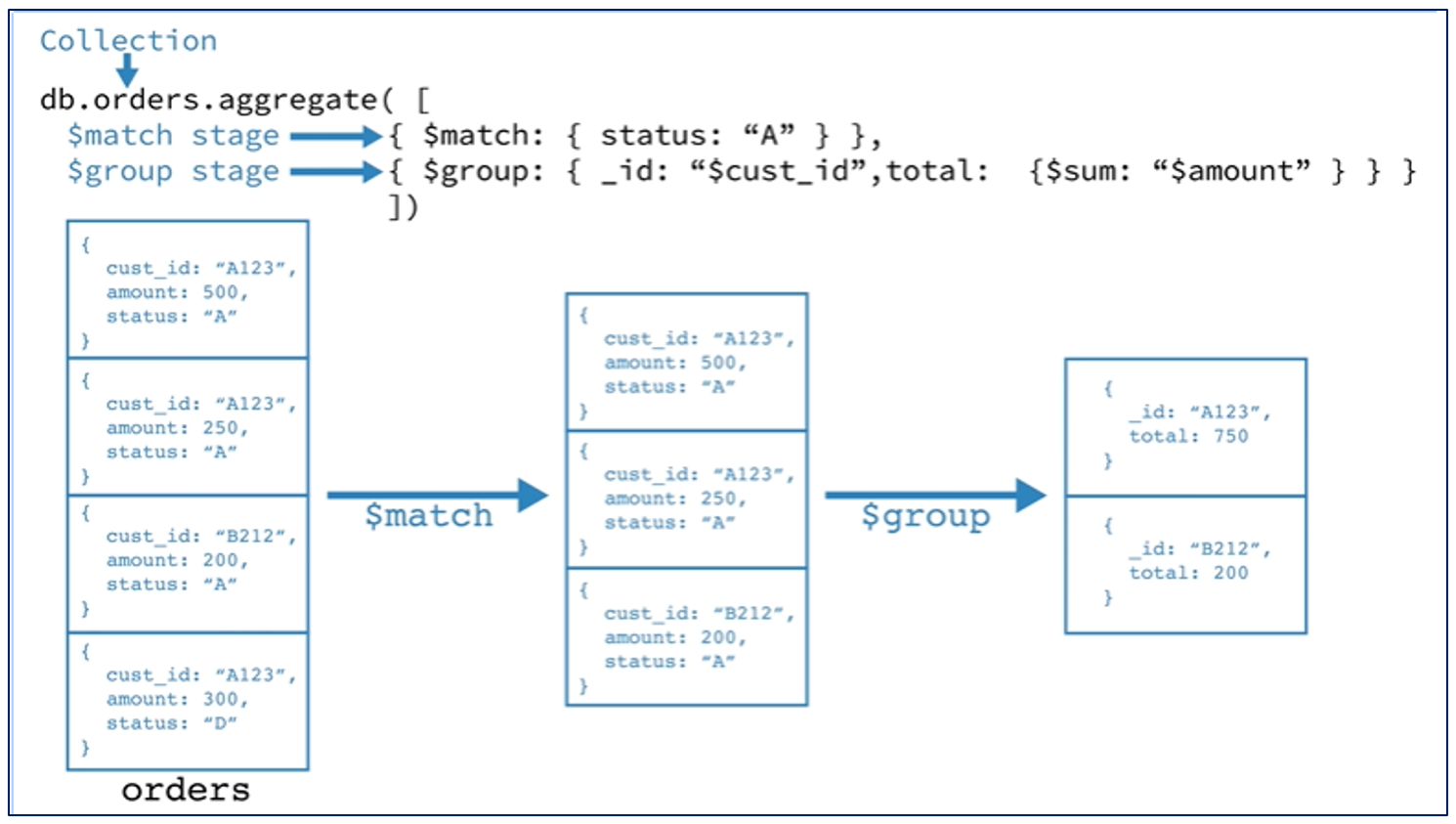
Aggregate 단계별 가공 예시 Collection Aggregate Stage
$out , $merge, $geoNear 는 여러번 사용할 수 있습니다.
Stage Description $addFields $set과 동일한 동작을 합니다. Document 에 새 Field 를 추가합니다. $bucket 지정된 표현식 및 버킷 범위설정을 기반으로 수신 문서를 버킷이라고하는 그룹으로 분류합니다. $bucketAuto $bucket 과 동일한 기능을 하지만 범위설정을 하지 않고 사용합니다. 범위는 모든 버킷이 균등하게 분류될 수 있는 범위로 자동 지정됩니다. $collStats 컬렉션이나 뷰에 대한 통계를 가져옵니다. $count Document 의 수를 가져옵니다. $facet 하나의 입력에 대한 다수의 집계 (ex. count, bucket ...) 에 대한 처리를 합니다. $geoNear 공간에 대한 근접성을 기반으로 정렬된 문서들을 가져옵니다. $graphLookup 재귀 검색을 수행합니다. 각 출력 문서에 해당 문서에 대한 재귀검색 순회결과를 포함하는 새 배열필드를 추가합니다. ($lookup 의 as 필드와 같이 추가하여 재귀횟수만큼 다수개 생성 ) $group 지정된 조건에 따라서 Document를 분류하여 그룹화합니다. $indexStats 인덱스 사용에 대한 통계를 가져옵니다. $limit 처음 n 개까지의 Document를 가져옵니다. $listSessions system.sessions 컬렉션에 오랫동안 활성상태였던 모든 세션을 가져옵니다. $lookup SQL JOIN 과 유사한 역활을 합니다. 두 컬렉션간 필드에 대하여 매칭하여 병합된 데이터를 보여줍니다. 병합된 컬렉션은 주 컬렉션의 Document 내에 필드로 추가됩니다. $match 지정된 조건에 따라 일치하는 Document 만 출력합니다. $merge $out 과 유사한 기능을 합니다. $out 결과에 대한 출력 컬렉션을 설정합니다. $planCacheStats 검색에 사용했던 쿼리가 Index 별로 어느정도의 효율이 보이는지, 최적의 index와 쿼리를 기준으로 Cache 에 저장해놓는것이 QueryPlan 이며, QueryPlan 에 대한 정보를 출력합니다. $project 특정 필드를 포함,추가,제외 하여 출력합니다. $redact 지정된 조건 및 엑세스 값에 따라서 각 Depth 별로 엑세스값이 일치하지 않는 경우, 필드나 Document를 제외하고 출력합니다. $replaceRoot Document를 지정된 결과의 하위 문서로 변경합니다. $replaceWith 와 동일한 기능입니다. $replaceWith Document를 지정된 결과의 하위 문서로 변경합니다. $replaceRoot 와 동일한 기능입니다. $sample Document 를 무작위로 선택합니다. $search 필드에 대한 전체 텍스트 검색을 수행합니다. $set Document 에 새 Field 를 추가합니다. $skip 처음 n개의 Document를 건너띄고 가져옵니다. $sort 지정된 키를 기준으로 정렬합니다. $sortByCount 지정된 표현식을 기준으로 그룹화 후 각 그룹별 Document의 수량을 가져옵니다. $unionWith 컬렉션간 결합을 수행합니다. $unset Document 에서 Field 를 제거합니다. $unwind 배열 필드를 분리하여 출력합니다.
예시)
Original Field -> a:[1,2]
Document1 -> a:1
Document2 -> a:2 )$merge vs $out
Subject $merge $out Version v4.2 Over v2.6 Over Output Target 동일, 타 Database Collection 동일 Database Collection Output Not Exist Collection Create Collection Create Collection Output Exist Collection 기존 Collection 과 병합가능 덮어쓰기 In/Output 에 대한 Sharded Collection 지원 모두 지원 입력에 대해서만 지원 Type as SQL MERGE
INSERT INTO T2 SELECT FROM T1
SELECT INTO T2 FROM T1INSERT INTO T2 SELECT FROM T1
SELECT INTO T2 FROM T1Database Aggregate Stage
Stage Description $currentOp MongoDB 배포의 활성 / 휴면 작업에 대한 정보를 반환합니다. $listLocalSessions 현재 연결된 인스턴스 mongos또는 mongod인스턴스 에서 최근 사용중인 모든 활성 세션을 나열 합니다. SQL to Aggregation Mapping Chart
SQL 기능과 Aggregate 함수의 Stage 기능은 유사할 뿐 기능상 차이점이 존재합니다.
SQL Terms, Functions, And Concepts MongoDB Aggregation Operators WHERE $match GROUP BY $group HAVING $match SELECT $project ORDER BY $sort LIMIT $limit SUM $sum COUNT $sum
$sortByCountJOIN $lookup SELECT INTO NEW_TABLE $out MERGE INTO TABLE $merge UNION ALL $unionWith Aggregate Variables
Variable Access via $$ Description NOW $$NOW 현재의 시간의 DateTime 반환합니다. CLUSTER_TIME $$CLUSTER_TIME 현재시간의 Timestamp 반환합니다. ROOT $$ROOT 최상위 문서를 참조합니다. CURRENT $$CURRENT Default 는 ROOT 이며, 변경될 수 있는 필드 경로의 시작점을 참조합니다. REMOVE $$REMOVE 필드의 조건부 제외를 허용합니다. DESCEND $$DESCEND $redact 식의 결과를 산정할 때 사용합니다. 문서의 포함여부 PRUNE $$PRUNE $redact 식의 결과를 산정할 때 사용합니다. 필드의 포함여부 KEEP $$KEEP $redact 식의 결과를 산정할 때 사용합니다. 모든 필드 반환여부 Aggregate Arithmetic Expression Operator
Name Description $abs 절대값을 반환 $add 합산 (숫자, 날짜) $cell 크거나 같은 가장 작은 수 반환 $divide 나누기 $exp 지수 지정 $floor 작거나 같은 가장 큰 수 반환 $ln 자연로그 계산 $log 지정된 값에 따른 로그 계산 $log10 지정된 값에 따른 로그 계산 $mod 나누고 남은 나머지값 $multiply 곱하기 $pow 지정된 수를 지수로 계산 $round 반올림 $sqrt 제곱근 $substract 빼기 $trunc 소수점 이하 절삭 Aggregate Array Expreesion Operator
Name Description $arrayElemAt 지정된 인덱스의 배열 요소 반환 $arrayToObject 배열을 key-value 형식으로 반환 $concatArrays 배열을 연결하여 반환 $filter 조건과 일치하는 배열요소만 반환 $first 첫번째 배열 요소를 반환 $in 특정값이 배열에 있는지 여부 $indexOfArray 배열에서 특정값의 최초 발견 위치 $isArray 배열인지 확인 $last 마지막 배열 요소를 반환 $map 지정된 식을 적용하고 명명된 필드명으로 변경하여 반환 $objectToArray key-value 형식을 배열로 치환 $range 일정 범위의 배열을 출력 $reduce 배열의 각 요소에 표현식을 적용하고 단일 값으로 결합 $reverseArray 배열을 역순으로 반환 $size 배열의 사이즈 반환 $slice 배열의 하위 집합을 반환 $zip 두 배열을 병합 Aggregate Bool Expression Operator
Name Description $and 모두 참인 경우 true 를 반환 $not 반대인 경우 true 를 반환 $or 하나의 조건이라도 참인 경우 true 로 반환 Aggregate Comparison Expression Operator
Name Description $cmp 두 값이 같으면 0, 첫 값이 크면 1, 두번째 값이 크면 -1 $eq 두 값이 동일한 경우 true 를 반환합니다. $gt 첫번째 값이 두번째 값보다 크면 true 를 반환합니다. $gte 첫번째 값이 두번째 값보다 크거나 같으면 true 를 반환합니다. $lt 첫번째 값이 두번째 값보다 작으면 true 를 반환합니다. $lte 첫번째 값이 두번째 값보다 작거나 같으면 true를 반환합니다. $ne 두 값이 동일하지 않으면 true 를 반환합니다. Aggregate Conditional Operator
Name Description $cond 두개의 식 중 하나의 값을 반환합니다. $ifNull 첫 번째 표현식이 Null 인 경우, 두번째 표현식의 결과를 반환합니다. $switch 지정된 식의 조건 중 일치되는 경우 true 를 반환합니다. Aggregate Custom Expression Operator
Name Description $accumulator 사용자 지정 누산기 함수를 정의합니다. $function 사용자 지정 함수를 정의합니다. Aggregate Data Size Expression Operator
Name Description $binarySize 문자열이나 이진데이터의 값을 byte 로 반환합니다. $bsonSize 주어진 문서를 BSON (byte) 크기로 반환합니다. Aggregate Date Expression Operator
Name Description $dateFromParts 날짜를 BSON Date 객체를 생성합니다. $dateFromString 날짜 / 시간 문자열을 날짜 개체로 변환합니다. $dateToParts 날짜를 포함하는 문서를 반환합니다. $dateToString 날짜를 형식화 된 문자열로 반환합니다. $dayOfMonth 날짜의 일을 1에서 31 사이의 숫자로 반환합니다. $dayOfWeek 날짜의 요일을 1 (일요일)에서 7 (토요일) 사이의 숫자로 반환합니다. $dayOfYear 1에서 366 (윤년) 사이의 숫자로 날짜의 일을 반환합니다. $hour 날짜의 시간을 0에서 23 사이의 숫자로 반환합니다. $isoDayOfWeek 1(월요일)부터 7(일요일) 까지 ISO 8601 형식으로 요일 숫자를 반환합니다 . $isoWeek 반환에 이르기까지 ISO 8601 형식으로 주 번호, 1에 53. 주 번호 1는 연도의 첫 번째 목요일이 포함 된 주 (월요일부터 일요일)로 시작합니다. $isoWeekYear ISO 8601 형식으로 연도 숫자를 반환합니다. $millisecond 날짜의 밀리 초를 0에서 999 사이의 숫자로 반환합니다. $minute 날짜의 분을 0에서 59 사이의 숫자로 반환합니다. $month 날짜의 월을 1 (1 월)에서 12 (12 월) 사이의 숫자로 반환합니다. $second 날짜의 초를 0에서 60 (윤초) 사이의 숫자로 반환합니다. $toDate 값을 날짜로 변환합니다. $week 날짜의 주 번호를 0 (연도의 첫 번째 일요일 이전의 부분 주)과 53 (윤년) 사이의 숫자로 반환합니다. $year 연도를 숫자로 반환합니다 (예 : 2014). Aggregate Literal Expression Operator
Name Description $literal 구문을 분석하지 않고 있는 그대로 값을 사용합니다. ( $set -> "$set" ) Aggregate Miscellaneous Expression Operator
Name Description $rand 0과 1 사이의 Random 한 값을 반환합니다. $sampleRate 랜덤으로 Document 를 반환합니다. Aggregate Object Expression Operator
Name Description $mergeObjects 다수의 Document 를 하나의 Document 로 합칩니다. $objectToArray key-value 를 배열로 변환합니다. Aggregate Set Expression Operator
배열 필드에 대한 Aggregate 에만 동작가능합니다.
Name Description $allElementsTrue 조건에 모든 배열 요소가 참인 경우 true, 아닐 경우 false $anyElementTrue 조건에 하나 이상의 배열 요소가 참인 경우 true $setDifference 두 번째 배열의 요소 값중 첫 번째 배열에 포함되지 않는 값을 반환합니다. $setEquals 두 배열이 같으면 true 를 반환합니다. 중복된 배열 요소 값은 무시합니다. $setIntersection 두 배열의 같은 배열 요소만 반환합니다. $setIsSubset 첫 번째 배열이 두 번째 배열의 부분 집합인 경우 true 를 반환합니다. $setUnion 두 개의 배열을 병합하여 반환합니다. Aggregate String Expression Operator
Name Description $concat 문자열을 연결합니다. $dateFromString 날짜 / 시간 문자열을 날짜 개체로 변환합니다. $dateToString 날짜를 형식화 된 문자열로 반환합니다. $indexOfBytes 문자열을 검색하고 찾은 위치의 바이트 인덱스를 반환합니다. 없을 경우 -1 을 반환합니다. $indexOfCP 문자열을 검색하고 찾은 위치의 코드 포인트형식으로 인덱스를 반환합니다. 없을 경우 -1 을 반환합니다. $ltrim 문자열 시작에서 공백 또는 지정된 문자를 제거합니다. $regexFind 정규식 (regex)을 문자열에 적용하고 일치 하는 첫 번째 문자열 에 대한 정보를 반환합니다 . $regexFindAll 정규식 (regex)을 문자열에 적용하고 일치하는 모든 문자열에 대한 정보를 반환합니다. $regexMatch 정규식 (regex)을 문자열에 적용하고 일치 항목이 있는지 여부를 나타내는 부울을 반환합니다. $replaceOne 문자열에서 조건에 일치하는 문자를 하나만 치환합니다. $replaceAll 문자열에서 조건에 일치하는 문자를 모두 치환합니다. $rtrim 문자열 끝에서 공백 또는 지정된 문자를 제거합니다. $split 구분 기호를 기준으로 문자열을 분할하며 배열을 반환합니다. 구분 기호가 문자열 내에서 발견되지 않으면 원래 문자열이 포함 된 배열을 반환합니다. $strLenBytes 문자열에서 UTF-8로 인코딩 된 바이트 수를 반환합니다. $strLenCP 문자열 의 UTF-8 코드 포인트 수를 반환합니다 . $strcasecmp 대소 문자를 구분하지 않는 문자열 비교를 수행하고, 두 문자열이 동일한 경우 0 , 첫 번째 문자열이 두 번째 문자열보다 큰 경우 1, 첫 번째 문자열이 두 번째 문자열보다 작은 -1경우를 반환합니다. $substrBytes 문자열의 부분을 반환합니다. 문자열에서 지정된 UTF-8 바이트 인덱스 (0부터 시작)에있는 문자로 시작하여 지정된 바이트 수 동안 계속됩니다. $substrCP 문자열의 부분을 반환합니다. 문자열의 지정된 UTF-8 코드 포인트 (CP) 인덱스 (0 부터 시작)에있는 문자로 시작하여 지정된 코드 포인트 수만큼 계속됩니다. $toLower 문자열을 소문자로 변환합니다. $toString 값을 문자열로 변환합니다. $trim 문자열의 시작과 끝에서 공백 또는 지정된 문자를 제거합니다. $toUpper 문자열을 대문자로 변환합니다. Aggregate Text Expression Operator
Name Description $meta 인덱스를 가져오거나 조건에 일치하는 Text 의 일치율을 반환하며 및 부가작업을 합니다. Aggregate Trigonometry(삼각함수) Expression Operator
Name Description $sin 라디안으로 측정 된 값의 사인을 반환합니다. $cos 라디안으로 측정 된 값의 코사인을 반환합니다. $tan 라디안으로 측정 된 값의 탄젠트를 반환합니다. $asin 라디안 값의 역사 인 (arc sine)을 반환합니다. $acos 라디안 값의 역 코사인 (아크 코사인)을 반환합니다. $atan 라디안 값의 역 탄젠트 (호 탄젠트)를 반환합니다. $atan2 라디안 값의 역 탄젠트 (호 탄젠트)를 반환합니다. $asinh 라디안 값의 역 쌍곡 사인 (쌍곡 아크 사인)을 반환합니다. $acosh 라디안 값의 역 쌍곡 코사인 (쌍곡 코사인)을 반환합니다. $atanh 라디안 값의 역 쌍곡 탄젠트 (쌍곡 아크 탄젠트)를 반환합니다. $sinh 라디안으로 측정되는 값의 쌍곡 사인을 반환합니다. $cosh 라디안으로 측정 된 값의 쌍곡 코사인을 반환합니다. $tanh 라디안으로 측정 된 값의 쌍곡 탄젠트를 반환합니다. $degreesToRadians 값을 각도에서 라디안으로 변환합니다. $radiansToDegrees 값을 라디안에서 각도로 변환합니다. Aggregate Type Expression Operator
Name Description $convert 값을 지정된 유형으로 변환합니다. $isNumber integer, decimal, double 또는 long 이면 true $toBool 값을 Bool로 변환합니다. $toDate 값을 날짜로 변환합니다. $toDecimal 값을 10진수로 변환합니다. $toDouble 값을 double로 변환합니다. $toInt 값을 정수로 변환합니다. $toLong 값을 long으로 변환합니다. $toObjectId 값을 ObjectId로 변환합니다. $toString 값을 문자열로 변환합니다. $type 필드의 BSON 데이터 유형을 반환합니다. Aggregate Accumulators
누산기능은 대체로 $Group Stage 에서 지정하여 사용합니다.
$avg, $max, $min, $stdDevPop, $stdDevSamp, $sum 은 $group Stage 가 아닌경우에도 활용할 수 있습니다.
Name Description $accumulator 사용자 정의 누산기 함수의 결과를 반환합니다. $addToSet 지정된 값을 추가합니다. $avg 숫자 값의 평균을 반환합니다. 숫자가 아닌 값을 무시합니다. $first 각 그룹의 첫 번째 문서에서 값을 반환합니다. 배열 연산자 $first와 다릅니다. $last 각 그룹의 마지막 문서에서 값을 반환합니다. 배열 연산자 $last와 다릅니다. $max 각 그룹에 대해 가장 큰 값을 반환합니다. $mergeObjects 각 그룹의 입력 문서를 결합하여 만든 문서를 반환합니다. $min 각 그룹에 대해 가장 작은 값을 반환합니다. $push 각 그룹에 대한 표현식의 결과를 배열로 추가하여 반환합니다. $stdDevPop 입력 값의 표준 편차를 반환합니다. $stdDevSamp 입력 값의 표본 표준 편차를 반환합니다. $sum 숫자 값의 합계를 반환합니다. 숫자가 아닌 값을 무시합니다. Aggregate Variable Expression Operator
Name Description $let 변수를 미리 정의하고 하위 식에서 사용합니다. 기본적인 aggregate 예시
sum, avg, min, max, last, first
//같은 name 값을 가진 document 끼리 묶어서 hits를 더하는 예시 //$sum 대신 $avg, $min, $max, $last, $first 와 같은 값을 동일하게 사용할 수 있습니다. > db.book.find() { "_id" : ObjectId("606d143ded469e92c204ac31"), "name" : "A", "hits" : 100, "auther" : [ { "name" : "park" }, { "name" : "lee" } ] } { "_id" : ObjectId("606d143ded469e92c204ac32"), "name" : "B", "hits" : 50, "auther" : [ { "name" : "kim" } ] } { "_id" : ObjectId("606d1474ed469e92c204ac33"), "name" : "C", "hits" : 30, "auther" : [ { "name" : "kim" }, { "name" : "choi" } ] } { "_id" : ObjectId("606e4b8b41b02ac25c437a9b"), "name" : "DD" } { "_id" : ObjectId("606e82a341b02ac25c437a9c"), "name" : "A", "hits" : 120, "auther" : [ ] } > db.book.aggregate([ {$group: { _id: { "name":"$name" }, sum_hits:{$sum:"$hits"} }}]) { "_id" : { "name" : "B" }, "sum_hits" : 50 } { "_id" : { "name" : "DD" }, "sum_hits" : 0 } { "_id" : { "name" : "C" }, "sum_hits" : 30 } { "_id" : { "name" : "A" }, "sum_hits" : 220 }addtoset, push
//addtoset 을 통해 auther 를 추가할 경우, name 이 A 인 doucment 들의 auther 가 Array 형식으로 추가되어 표출 //아래 aggregate 와 같이 expression 을 두개이상도 같이 사용가능 //addtoset 과 push 의 차이점은 addtoset은 중복제거 > db.book.find() { "_id" : ObjectId("606d143ded469e92c204ac31"), "name" : "A", "hits" : 100, "auther" : [ { "name" : "park" }, { "name" : "lee" } ] } { "_id" : ObjectId("606d143ded469e92c204ac32"), "name" : "B", "hits" : 50, "auther" : [ { "name" : "kim" } ] } { "_id" : ObjectId("606d1474ed469e92c204ac33"), "name" : "C", "hits" : 30, "auther" : [ { "name" : "kim" }, { "name" : "choi" } ] } { "_id" : ObjectId("606e4b8b41b02ac25c437a9b"), "name" : "DD" } { "_id" : ObjectId("606e82a341b02ac25c437a9c"), "name" : "A", "hits" : 120, "auther" : [ ] } { "_id" : ObjectId("606e9bf241b02ac25c437a9d"), "name" : "A", "hits" : 120, "auther" : [ { "name" : "kim" }, { "name" : "woo" } ] } > db.book.aggregate([ {$group: { _id: { "name":"$name" }, auther:{$addToSet:"$auther"}, sum_hits:{$sum:"$hits"} }, } ]) { "_id" : { "name" : "B" }, "auther" : [ [ { "name" : "kim" } ] ], "sum_hits" : 50 } { "_id" : { "name" : "A" }, "auther" : [ [ { "name" : "park" }, { "name" : "lee" } ], [ ], [ { "name" : "kim" }, { "name" : "woo" } ] ], "sum_hits" : 340 } { "_id" : { "name" : "C" }, "auther" : [ [ { "name" : "kim" }, { "name" : "choi" } ] ], "sum_hits" : 30 } { "_id" : { "name" : "DD" }, "auther" : [ ], "sum_hits" : 0 }double grouping
double grouping은 aggregate한 결과를 가지고 다시한번 aggregate해주는 방법
> db.book.aggregate([ {$group:{_id:{"name":"$name"}, sum_hits:{$sum:"$hits"} } }, {$group:{_id:"", avg_hits:{$avg:"$sum_hits"}} } ]) /* 앞선 group aggregate 결과 { "_id" : "A", "avg_hits" : 340 } { "_id" : "B", "avg_hits" : 50 } { "_id" : "DD", "avg_hits" : 0 } { "_id" : "C", "avg_hits" : 30 } */ { "_id" : "", "avg_hits" : 105 }Join 과 같이 활용
MongoDB 에서는 Collection 간 lookup 을 사용하기 보다는 Embedded Data Models 의 사용을 권고합니다. 또한 lookup 은 sharded collection 에 대해서는 제약사항이 존재합니다.
> db.orders.insert([{ "_id" : 1, "item" : "abc", "price" : 12, "quantity" : 2 }, { "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1 }, { "_id" : 3 }]); > db.inventory.insert([{ "_id" : 1, "sku" : "abc", description: "product 1", "instock" : 120 }, { "_id" : 2, "sku" : "def", description: "product 2", "instock" : 80 }, { "_id" : 3, "sku" : "ijk", description: "product 3", "instock" : 60 }, { "_id" : 4, "sku" : "jkl", description: "product 4", "instock" : 70 }, { "_id" : 5, "sku": null, description: "Incomplete" }, { "_id" : 6 }]); //localField(aggregate collection) , foreignField(from collection) 조인할 키값 //as 는 inventory 의 정보가 담깁니다. //out 이 없는 경우 결과 출력만 진행 > db.orders.aggregate([ { $lookup: { from: "inventory", localField: "item", foreignField: "sku", as: "inventory_docs" } }, { $out : "coltest1" } ]) > db.coltest1.find() { "_id" : 1, "item" : "abc", "price" : 12, "quantity" : 2, "inventory_docs" : [ { "_id" : 1, "sku" : "abc", "description" : "product 1", "instock" : 120 } ] } { "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1, "inventory_docs" : [ { "_id" : 4, "sku" : "jkl", "description" : "product 4", "instock" : 70 } ] } { "_id" : 3, "inventory_docs" : [ { "_id" : 5, "sku" : null, "description" : "Incomplete" }, { "_id" : 6 } ] }참조 : https://docs.mongodb.com/manual/reference/operator/aggregation-pipeline/
참조 : https://docs.mongodb.com/manual/reference/operator/aggregation/
참조 : https://docs.mongodb.com/manual/meta/aggregation-quick-reference/
'Database > MongoDB' 카테고리의 다른 글
Index (1) 2023.02.02 MapReduce (0) 2023.02.02 Operator & Function (0) 2023.02.01 기본 Query (0) 2023.02.01 What is MongoDB? (0) 2023.02.01