-
Kafka ConnectorMSA/Kubernetes 2023. 2. 9. 19:41
kafka Connect
Kafka Connect는 Apache Kafka®와 다른 데이터 시스템간에 데이터를 확장 가능하고 안정적으로 스트리밍하기위한 도구입니다.
대규모 데이터 세트를 Kafka 안팎으로 이동하는 커넥터를 간단하게 정의 할 수 있습니다. Kafka Connect는 전체 데이터베이스를 수집하거나 모든 애플리케이션 서버의 메트릭을 Kafka 토픽으로 수집하여 짧은 대기 시간으로 스트림 처리에 데이터를 사용할 수 있습니다.
Kafka Connect는 데이터베이스, 키-값 저장소, 검색 색인 및 파일 시스템 간의 간단한 데이터 통합을위한 중앙 집중식 데이터 허브로 작동하는 Apache Kafka®의 무료 오픈 소스 구성 요소입니다.
Kafka Connect 장점
- 데이터 중심 파이프 라인 – Connect는 의미있는 데이터 추상화를 사용하여 데이터를 Kafka로 가져 오거나 푸시합니다.
- 유연성 및 확장 성 – Connect는 단일 노드 (독립 실행 형)에서 스트리밍 및 배치 지향 시스템으로 실행되거나 조직 전체 서비스로 확장 (분산)됩니다.
- 재사용 성 및 확장 성 – Connect는 기존 커넥터를 활용하거나 필요에 맞게 확장하여 생산 시간을 단축합니다.
Kafka Connect는 Kafka와주고받는 데이터 스트리밍에 중점을 두어 고품질의 안정적인 고성능 커넥터 플러그인을 더 간단하게 작성할 수 있도록합니다. Kafka Connect를 사용하면 프레임 워크가 다른 프레임 워크를 사용하여 달성하기 어려운 보장을 할 수도 있습니다. Kafka Connect는 Kafka 및 스트림 처리 프레임 워크와 결합 될 때 ETL 파이프 라인의 필수 구성 요소입니다.
Kafka Connect 작동 방식
Kafka Connect를 단일 시스템 (예 : 로그 수집)에서 작업을 실행하는 독립 실행 형 프로세스로 배포하거나 전체 조직을 지원하는 분산되고 확장 가능한 내결함성 서비스로 배포 할 수 있습니다. Kafka Connect는 진입 장벽이 낮고 운영 오버 헤드가 낮습니다. 개발 및 테스트를위한 독립 실행 형 환경으로 소규모로 시작한 다음 대규모 조직의 데이터 파이프 라인을 지원하기 위해 전체 프로덕션 환경으로 확장 할 수 있습니다.
Kafka Connector 유형
- 소스 커넥터 – 전체 데이터베이스를 수집하고 테이블 업데이트를 Kafka 주제로 스트리밍합니다. 소스 커넥터는 또한 모든 애플리케이션 서버에서 메트릭을 수집하고이를 Kafka 토픽에 저장하여 짧은 대기 시간으로 스트림 처리에 데이터를 사용할 수 있습니다. ( Producer )
- 싱크 커넥터 – Kafka 주제의 데이터를 Elasticsearch와 같은 보조 인덱스 또는 오프라인 분석을 위해 Hadoop과 같은 배치 시스템으로 전달합니다. ( Consumer )
필요에 따라 만들수도 있다.
다양한 제품을 기본 제공하기도 한다. Mongodb, PostgreSQL, Mysql, mssql, redis, rabbitmq, etc...
Reference : https://docs.confluent.io/home/connect/supported.html
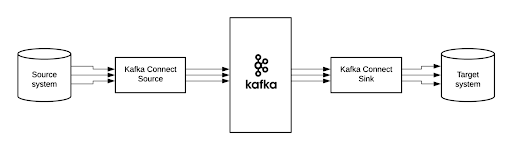
Kafka Connector 
kafka connect Schema Registry
스키마 레지스트리는 카프카 클라이언트 사이에서 메시지의 스키마를 저장, 관리하는 웹 어플리케이션입니다. 카프카 개발자와 운영자들이 카프카 운영에 필수로 꼽습니다. 이처럼 스키마 레지스트리는 운영과 밀접한데, 그 이유에 대해서 먼저 살펴봅니다.
등장 배경
카프카는 클라이언트 사이의 관계를 끊습니다. 즉, 프로듀서는 어떤 컨슈머가 메시지를 가져갈 지 모릅니다. 컨슈머는 어떤 프로듀서가 메시지를 보냈었는 지 모릅니다.
그리고 브로커는 메시지를 저장을 로그(Log)라는 자료구조 형태로 저장합니다.
이 로그 자료구조는 일반적으로 우리가 언급하는 시스템 로그, 애플리케이션 로그 등의 추상화된 자료구조입니다. 가장 큰 특징은 Append-Only인데, 다음과 같은 속성을 가집니다.a. 쓰기 작업은 가장 말단에서만 실행된다. b. 중간 수정 작업을 할 수 없다.목적과 기능
클라이언트 사이에는 여전히 메시지 구조에 대한 강한 결합도를 가지고 있습니다. 스키마 레지스트리는 이 결합도를 낮추기 위해 고안되었습니다.
스키마 레지스트리는 카프카 외부에 구성되어, 클라이언트와 통신합니다. 스키마 레지스트리는 별도의 웹 어플리케이션 형태로 구성되며, 기능은 다음과 같습니다.
a. 토픽 별 메시지 Key 또는 Value 스키마 버전 관리 b. 스키마 호환성 규칙 강제 c. 스키마 버전 조회위 세 가지 기능들을 중 가장 핵심은 2번(스키마 호환성 규칙 강제)입니다.
운영자는 스키마를 등록하여 사용할 수 있지만, 스키마 버전 별 호환성을 강제함으로써 일종의 개발 운영 규칙을 세우는 것입니다.
스키마 호환성은 크게 Backward, Forward, Full, None 이 있습니다. 간단히 버전 1,2 스키마를 예를 들어 설명하면 다음과 같습니다.
a. Backward : 컨슈머는 2번 스키마로 메시지를 처리하지만 1번 스키마도 처리할 수 있습니다. 필드 삭제 혹은 기본 값이 있는 필드 추가인 경우 b. Forward : 컨슈머는 1번 스키마로 메시지를 처리하지만 2번 스키마도 처리할 수 있습니다. 필드 추가 혹은 기본 값이 있는 필드 삭제 c. Full : Backward와 Forward를 모두 가집니다. 기본 값이 있는 필드를 추가 혹은 삭제 d. None : 스키마 호환성을 체크하지 않습니다.
참조 1. schema registry 
참조 2. Schema registry Debezium ( Kafka Connect PlugIn 중 하나 )
유래 : DBs + ium (주기율표의 원소이름에 붙이는 접미사)
(Dbs-ium)
=> Dee-BEE-zee-uhm
=> Debezium- 카프카 Source 커넥터의 집합이다. CDC를 사용하여 데이터베이스의 변경 사항을 수집한다.
- 데이베이스의 로우 레벨의 변경 사항을 캡처하여 애플리케이션이 변경 내용을 보고 이를 처리할 수 있도록 해주는 분산 서비스이다.
- Debezium은 모든 로우 레벨의 변경을 changed event stream에 기록한다. 애플리케이션은 이 스트림을 통해 변경 이벤트을 순서대로 읽는다.
- Debezium은 다양한 커넥터들을 제공한다. Debezium의 목표는 다양한 DBMS의 변경 사항을 캡쳐하고 유사한 구조의 변경 이벤트를 produce 하는 커넥터 라이브러리를 구축하는 것이다. 현재는 MongoDB, MySQL, PostgreSQL, SQL Server, Oracle, Db2, Cassandra 등을 지원한다.
- Trivago, Wepay, Yotpo, BlaBlaCar에서 적용되어 있다

CDC
데이터베이스의 CDC (Change Data Capture)는 변경된 데이터를 사용해 액션(Action)이 취하도록 변경된 데이터를 판별 및 추적하는 데 사용되는 소프트웨어 설계 패턴이다.
- 변경된 내용을 실시간으로 취득하는 기술이다.
- DBMS들은 CUD 작업전에 작업 내용을 Logging한다 (write-ahead-logging). CDC는 Source DB의 로그을 읽어 변경된 내용을 Target DB에 적용한다.
- OGG(Oracle Golden Gate), Debezium 등이 대표적이다.
- CDC는 주로 Incremental Indexing에 사용된다.
• 일반적으로 서비스 초기에 데이터는 데이터 베이스에 저장된다
• 실시간 처리가 가능하다
• 새벽마다 통계 및 분석 를 위한 대량 배치 작업을 줄일 수 있다
• 데이터 변경분만 전송되기에 훨씬 효율적이고 필요한 자원이 줄어 든다Features
- 모든 데이터 변경이 캡쳐된다.
- 변경 이벤트를 큰 딜레이없이 생성한다.
- data model 변경을 필요로 하지 않는다.
- 변경뿐만 아니라 삭제도 캡쳐한다.
- 레코드의 과거 상태도 캡처가능 하다.
Debezium CDC
- Snapshots : 커넥터가 시작될 때 데이터베이스의 현재 상태에 대한 초기 스냅샷을 생성할 수 있다. 스냅샷을 위한 다른 모드가 존재한다.
- Filters : 특정 테이블이나 칼럼의 변경만 캡쳐하도록 설정할 수 있다.
- Masking : 민감한 정보의 경우 특정 칼럼을 마스킹처리할 수 있다.
- Monitoring : 대부분의 커넥터들은 JMX를 사용해서 모니터링 될 수 있다.
- Messsage Transformations : message routing, routing of events
• 스키마 레지스트리(Schema Registry)와 잘 연동한다
• DML과 DDL이 카프카 토픽에 저장한다. Mysql bin log position(offset) 정보 및 Schema 정보를 저장한다. 따라서 복제 인자(replication factor)가 중요하다. 복제 인자가 1이면 데이터가 깨져서 고생할 수 있다.
• Schema 토픽 데이터가 깨지면 Debezium이 정상적으로 동작하지 않는다. debezium 설정에 "snapshot.mode":"schema_only_recovery "로 변경해 테이블 스키마와 데이터를 처음부터 카프카 토픽에 다시 저장하게 한다.
• Debezium이 카프카 토픽에 저장하는 데이터의 Mysql GTid, Mysql bin log는 이벤트마다 저장한다.
• Debezium/카프카 커넥트가 중단되었다가 재시작되면 Debezium은 마지막에 저장된 Mysql binlog position(offset) 부터 다시 읽어 카프카 토픽에 저장한다.
• Debezium이 토픽에 저장하는 before, after 레코드 필드는 Mongodb의 Oplog를 연상한다.
• 참고로 Debezium PostgresSQL 버전에는 JPA – Local 캐시 연동이 가능하다.• 논리적 복제를 사용해 변경 스트림을 아파치 카프카 토픽에 복제한다
• 데이터 덤프Architecture
- 가장 일반적으로 Debezium은 카프카 커넥터를 통해 배포된다.
- Source 커넥터는 데이터를 카프카에 모으는 역할을 한다. (예 : Debezium)
- Sink 커넥터는 카프카 토픽에 있는 데이터를 다른 시스템으로 전파하는 역할을 한다.
- MySQL, Postgres 용 Debezium 커넥터는 데이터베이스의 변경사항을 캡쳐하기 위해 배포된다. 커넥터는 클라이언트 라이브러이를 사용하여 Source 데이터베이스에 커넥션을 맺고, MySQL의 경우 bilog에 액세스하고 Postgres의 경우 logical replication stream을 읽는다.
- 기본적으로 한 테이블의 변경 사항은 하나의 토픽으로 전달된다.
- topic routing SMT 를 사용하면 토픽의 이름을 변경하거나 여러개의 테이블의 변경사항을 하나의 토픽으로 전달할 수 있다.
- 변경 이벤트가 카프카에 있으면, 서로 다른 커넥터를 사용하여 변경 사항을 Elasticsearch, Data warehouses, cache 등에 반영할 수 있다.
- Debezium 커넥터를 사용하는 다른 방법은 Embedded Engine을 사용하는 것이다. 이 경우 Debezium은 카프카 커넥터를 통해 실행되지 않고 자바 애플리케이션의 라이브러리로 사용된다. Embedded Engine는 변경 이벤트를 애플리케이션에서 바로 consuming하거나 변경 내역을 Amazon Kinesis와 같은 다른 메시지 브로커로 전달하고자 할 때 유용하다.
'MSA > Kubernetes' 카테고리의 다른 글
Kubernetes 개요 (0) 2023.02.15 Kafka Consumer Group 및 Rebalancing (0) 2023.02.10 Kafka 설치 (0) 2023.02.10 Kafka 기본 개념 (0) 2023.02.08 Helm Chart (0) 2023.02.02